I'm currently working as a software engineer at NewsBreak, a leading intelligent app focus on local news. Before that, I was a NSF funded Ph.D. researcher in Department of Computer Science at North Carolina State University under the supervision of Dr. Tim Menzies. I joined the Real-world Artificial Intelligence for Software Engineering (RAISE) lab in 2017.
Before coming to NC State, I earned my M.S. degree of Computer Science from The University of Texas at Dallas in 2015, where I also finished courseworks of Electrical and Computer Engineering (mainly focusing on VLSI Circuit Design and Computer Architecture). I did my undergrad at Nanjing University of Posts and Telecommunications, China, where I got my B.S. degree of Microelectronics in 2013.
My research interests include using data mining and artificial intelligence methods to solve real-world problems in software engineering field. Such as exploring new techniques in search-based optimization to improve the performance of current SE predicting tasks (like effort estimation, text mining, software health, etc.). I believe these software engineering tasks do not always need to be hard (but it may not be easy to find the easy ways to do it) and enjoy finding the path to make them better and better.
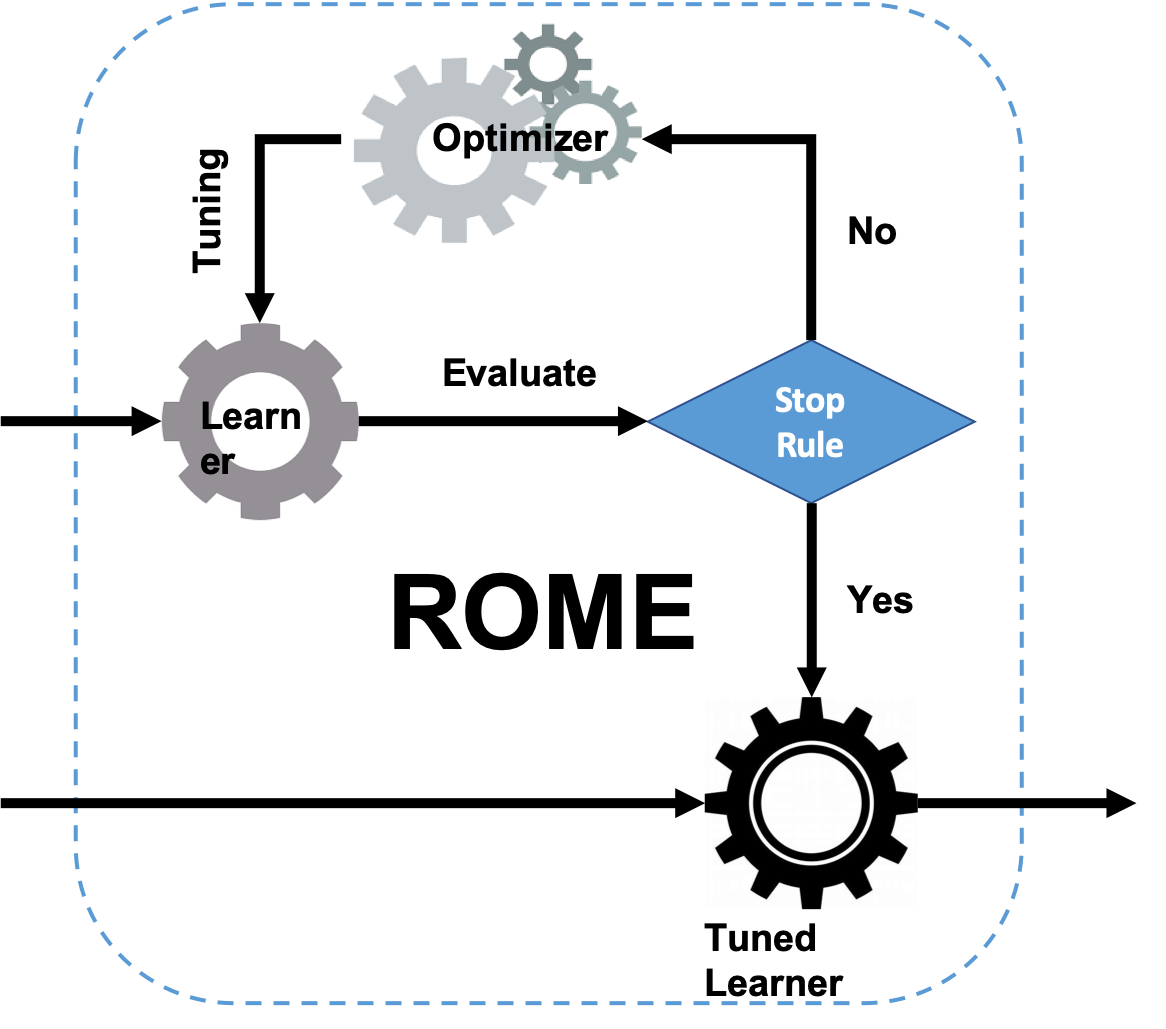
Tianpei Xia, Rui Shu, Xipeng Shen, Tim Menzies
Transactions on Software Engineering (TSE), 2020
Many methods have been proposed to estimate how much effort is required to build and maintain software. Much of that research tries to recommend a single method – an approach that makes the dubious assumption that one method can handle the diversity of software project data. To address this drawback, we apply a configuration technique called “ROME” (Rapid Optimizing Methods for Estimation), which uses sequential model-based optimization (SMO) to find what configuration settings of effort estimation techniques work best for a particular data set.
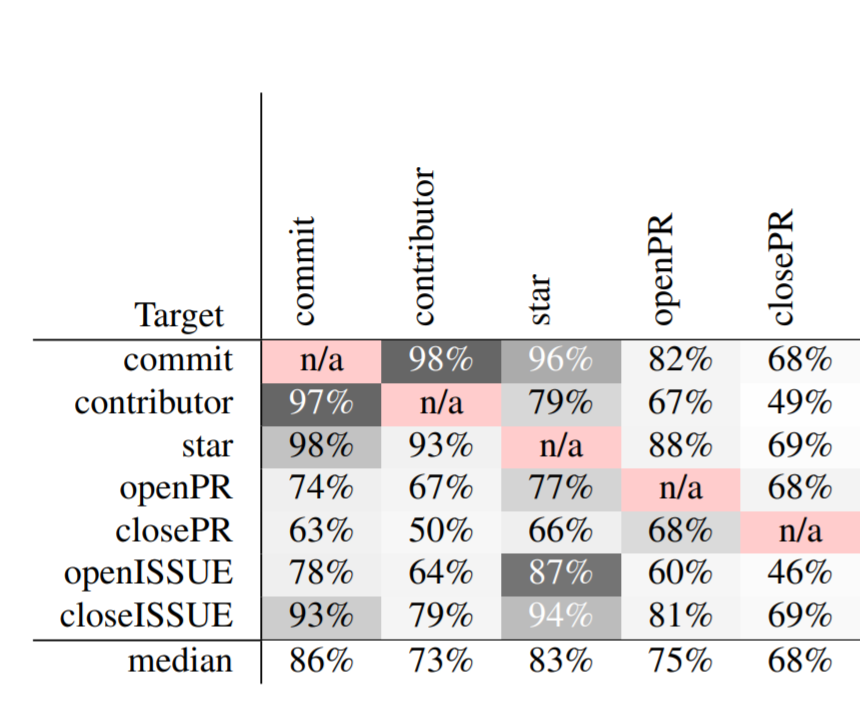
Tianpei Xia, Wei Fu, Rui Shu, Rishabh Agrawal, Tim Menzies
Empirical Software Engineering (EMSE), 2022
Software developed on public platforms are a source of data that can be used to make predictions about those projects. While the activity of a single developer may be random and hard to predict, when large groups of developers work together on software projects, the resulting behavior can be predicted with good accuracy. In this study, we use 78,455 months of data from 1,628 GitHub projects to make various predictions about the current status of those projects. The predicting error rate can be greatly reduced using DECART hyperparameter optimization.
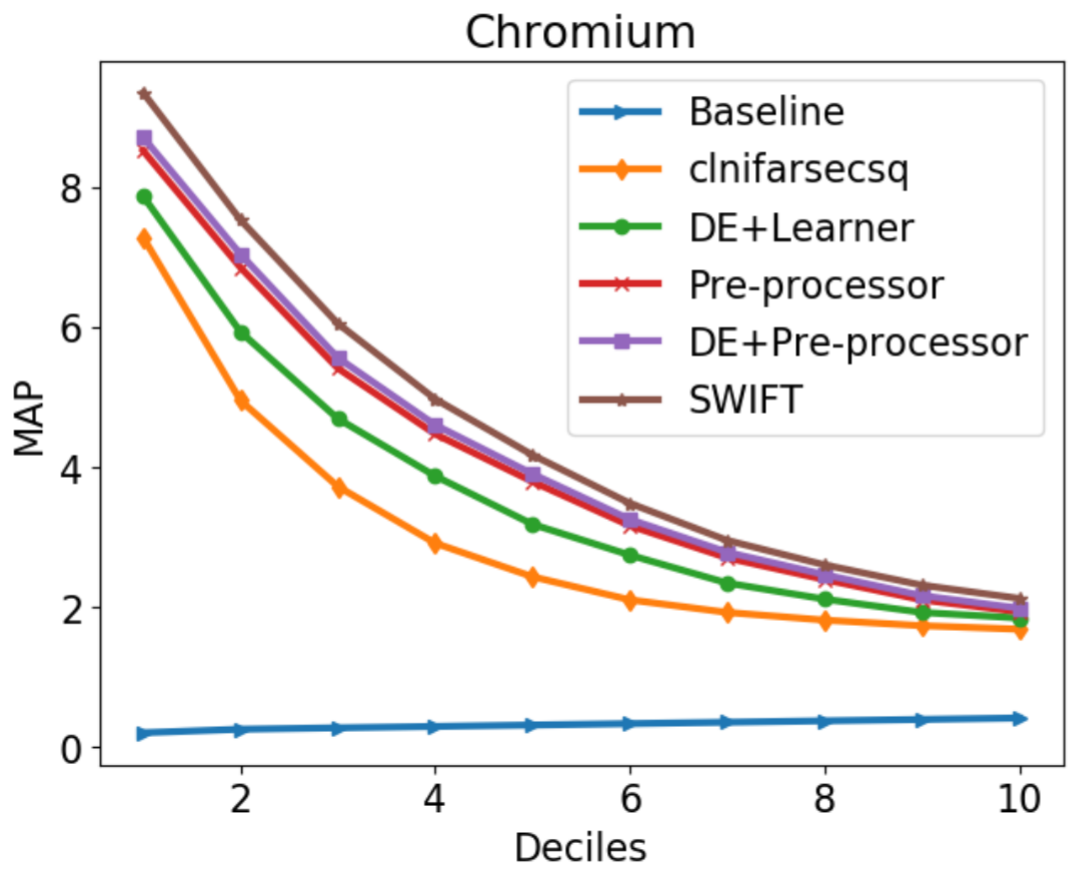
Rui Shu, Tianpei Xia, Jianfeng Chen, Laurie Williams, Tim Menzies
Empirical Software Engineering (EMSE), 2021
In order that the general public is not vulnerable to hackers, security bug reports need to be handled by small groups of engineers before being widely discussed. But learning how to distinguish the security bug reports from other bug reports is challenging since they may occur rarely. Data mining methods that can find such scarce targets require extensive optimization effort. Our approach can quickly optimize models that achieve better recalls than the prior state-of-the-art. These increases in recall are associated with moderate increases in false positive rates.
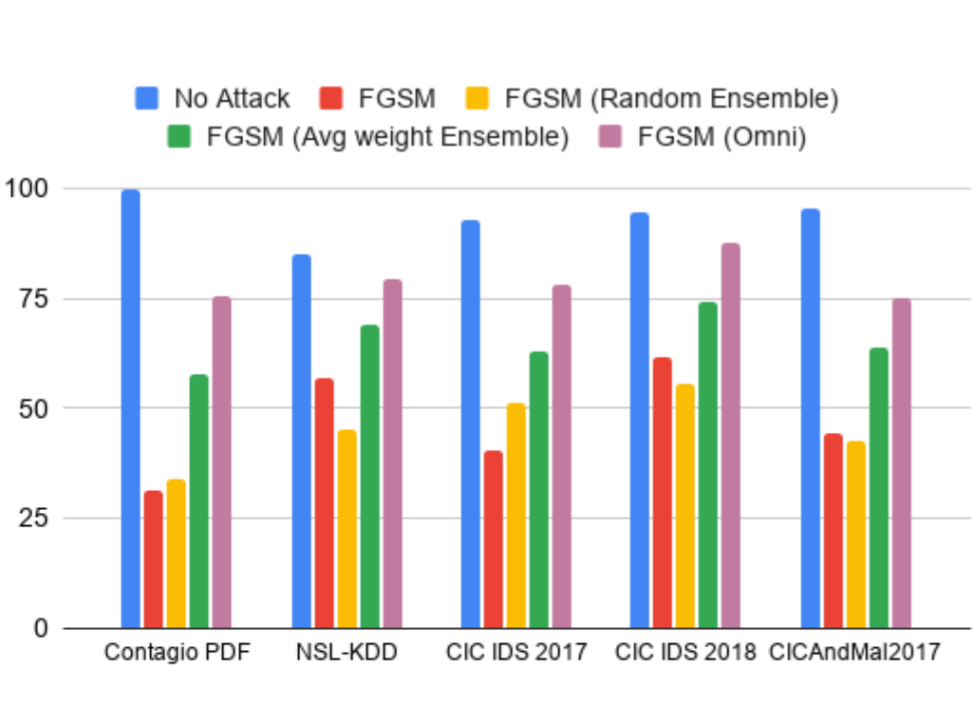
Rui Shu, Tianpei Xia, Laurie Williams, Tim Menzies
Empirical Software Engineering (EMSE), 2022
Machine learning-based security detection models have become prevalent in modern malware and intrusion detection systems. However, such models are susceptible to adversarial evasion attacks. In this type of attack, inputs are specially crafted by intelligent malicious adversaries, with the aim of being misclassified by existing state-ofthe-art models. Our methods can help security practitioners and researchers build a more robust model against adversarial evasion attack through the use of ensemble learningwith hyperparameter optimization.

